






In mid-March of 2020, virtually every school in America (and most worldwide) closed its doors for in-person instruction due to COVID lockdowns. Throughout the U.S., schools stayed closed through the spring. This early period of school closures hit every state and every school district, regardless of political or economic orientation.
In the summer and fall of 2020, however, school districts were left to make their own choices about whether to reopen. Some did and some did not. Those decisions, and their repercussions for kids, are still a topic of debate. I spent a lot of my time during the pandemic involved in that debate — collecting data, but also advocating for a position I believed in (which was that more schools should be open).
Five years out from those early days, we’ve had time to see the pandemic’s impact on kids, at least through their school performance, and to start to look at what seems like a long road to recovery. I’ve continued to work on these issues, particularly on test score recovery, and that’s what I want to talk about here.
Specifically, I want to cover a few things. First, since time robs us of clarity, I’ll briefly review the patterns of school closures in the 2020-2021 school year. Second, I’ll talk about what happened to test scores during COVID. Third, and most importantly, I’ll talk about what we are seeing in recovery and consider where we go from here, especially in light of recent changes at the Department of Education.
What happened with schools during COVID?
As noted, in March 2020, virtually every school in America closed its doors for in-person learning. When school districts reopened for the 2020-2021 school year (sometime between July and September 2020), they made various choices.
Some schools reopened for full in-person learning, some stayed fully remote, and some were hybrid (this took many forms). These decisions were made by individual school districts, since that is where the authority lies. States played an important role in making it easier or harder for districts to open, but ultimately this was a district-by-district decision.
The map below shows the patchwork of school openings in October 2020.
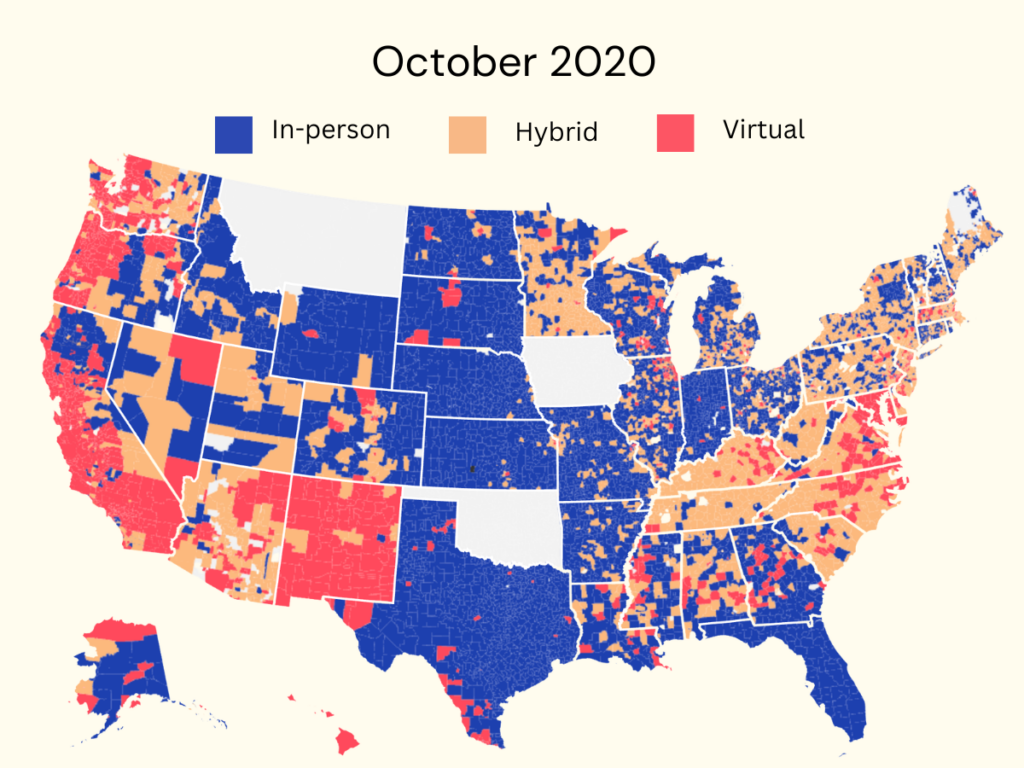
The most important determinant of school reopening in fall 2020 was political bent. Republican states and districts were more likely to open. This is largely due to their alignment with President Trump, who expressed a desire to see schools reopen. A secondary determinant was income. Within states, richer school districts were more likely to reopen (this was true for several reasons — most importantly, more parental pressure and more resources to add things like ventilation and COVID testing).
School districts that did not open early in fall 2020 generally did not reopen until spring 2021 (if at all). The map below shows the state of things in April 2021. We can see much more in-person schooling, but there are still districts that were fully remote. There are many districts, especially in California, that did not have any in-person schooling between March 2020 and September 2021.
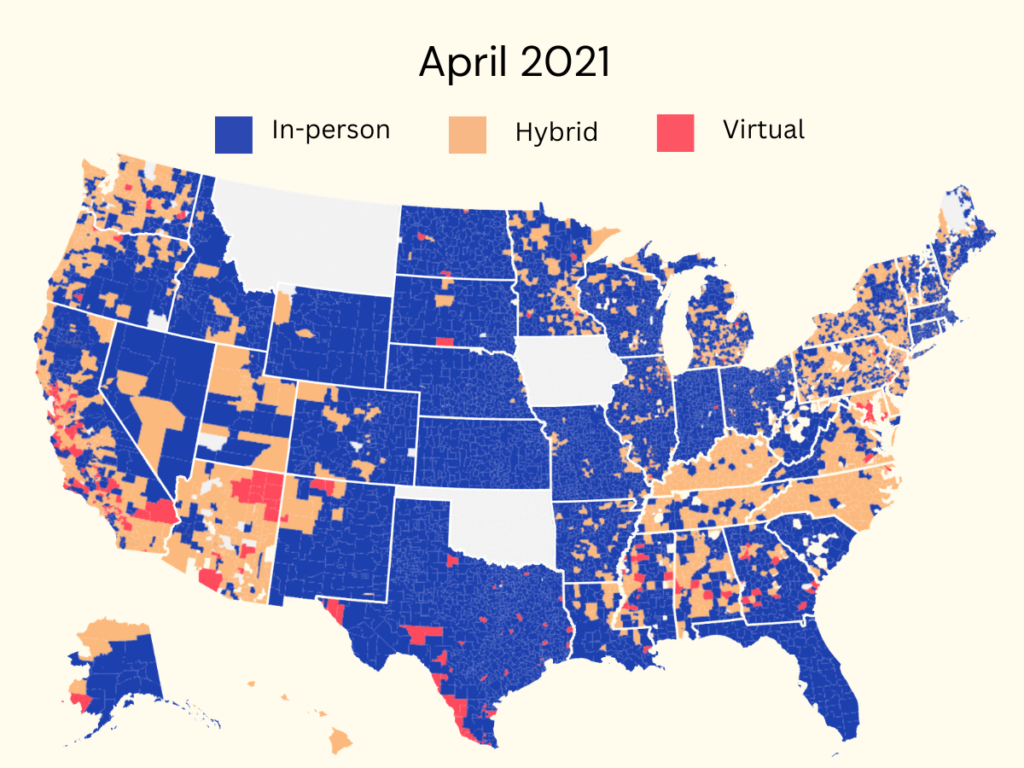
I review this here not to re-engage anger or unhappy memories but to remind people of the extent of disruptions, as a context for recovery.
What happened to test scores?
In the U.S., there are two primary ways we know about how kids are doing in school. The first is that, every year, each state tests every student in grades 3 through 8 in English language arts (ELA) and math. These tests are frequent and comprehensive, but the test is different in every state, so they are not nationally comparable. These tests were not given in spring 2020, when schools were closed. The first post-pandemic testing was in spring 2021.
The second is that the federal Department of Education tests fourth and eighth grade children in a randomly chosen subset of school districts every other year with tests that are designed to be comparable over time (and they give the same test in every state). These tests — called the National Assessment of Educational Progress — are our most consistent way to track test scores over time. They were not given in 2020 or 2021, so the first post-pandemic testing year was 2022.
Regardless of which metric you look at, test scores declined during the pandemic. This is something you’ve probably heard many times, so I will not belabor it. In spring 2021, at the end of that disrupted pandemic school year, test scores had declined across the board, in every state that performed an assessment.
The declines were larger in states and districts with more remote learning. In many cases, the changes were extremely large. The share of students in Virginia who were rated proficient in math, for example, fell by 30 percentage points between 2019 and 2021.
What has recovery looked like?
While these initial test score declines are striking, it’s particularly important to look at what’s happened since then. Beginning in fall 2021, everyone was back to school fully in person. This means that by spring 2024, the last time states gave assessments, there had been three full school years.
To give a sense of the recovery, I present two graphs below — the first is for ELA, and the second is for math. We’ve worked hard to get a lot of information into these graphs, so here’s what they show.
How to read the graphs
These graphs are looking at proficiency rates, or the share of students the state deems proficient in ELA or math. For each state, we first have a red dot that represents the initial pandemic test score change between 2019 and 2021-22 (these are all declines). The blue dot then represents the difference between 2024 proficiency rates and 2019 rates. This tells us how the state is doing now relative to pre-pandemic.
Where the line is blue — where the blue dot is to the right of the red one — we’re seeing recovery. Where the line is red — where the blue dot is to the left of the red one — we’re seeing continued declines post-pandemic.
ELA scores
The first graph here shows the scores in ELA — reading and writing. During the pandemic, score drops varied from almost no change (Iowa, Idaho) to a drop of almost 13 percentage points (Delaware). Post-pandemic, recovery has been extremely uneven.
There are some notable successes. South Carolina’s proficiency rates in 2024 were 8 percentage points above their pre-pandemic average. Mississippi recovered from a 10 percentage point decline to be significantly above its pre-pandemic level. Tennessee, West Virginia, Iowa, and Ohio have also seen gains.
There are also some large drops. Massachusetts, Oregon, Missouri, and Kansas have all seen continued declines in reading scores post-pandemic.
Math scores
The pattern in math shows less variation across states in recovery. The drops in test scores during the pandemic were larger on average. Every state has shown significant recovery post-pandemic, but few have seen a complete recovery. Mississippi is the only state where the 2024 scores are a lot higher than in 2019. This is notable, especially given their enormous pandemic drop.
Overall, it is clear there has been recovery post-pandemic and the enormous drops have not remained. On the other hand, the average proficiency rates across states are still not where they were before the pandemic. There is more work to be done.
Where do we go from here?
I spend a lot of time looking at these data as part of my work with the Education Data Center, and in my view there are two clear takeaways.
First: The variation in recovery across states should be an opportunity for learning. Even though the states do not all take the same test, I believe that we must be able to learn something general from states with better recovery. Not to put too fine a point on it, but what is Mississippi doing that Massachusetts is not? State education offices do not always speak to each other, but maybe they should.
Second: We need to continue to collect and analyze data like this, since understanding these patterns is key to finding policies that work. It’s key to celebrating successes and to holding failures to account. If we do not measure things, we tend not to focus on improving them. And improving schools should be a priority.
This point is especially important now, as cuts at the Department of Education threaten our ability to measure student achievement. The group that runs the National Assessment of Educational Progress has been gutted, making it hard to see how that test will be done in the future. Historical state test score data, which are housed in the Department of Education, may vanish. Ultimately, just like with school closures during the pandemic, the group this lack of data will hurt is kids.
The bottom line
- In March 2020, virtually every school in America closed its doors for in-person learning. When school districts reopened for the 2020-2021 school year, districts across the country varied in their approach, whether fully remote, fully in-person, or hybrid.
- Test scores on both state and federal levels declined during the pandemic. The declines were larger in states and districts with more remote learning.
- There has been recovery post-pandemic, and the enormous drops have not remained. However, the average proficiency rates across states are still not where they were before the pandemic.













Log in
Why are some states missing from the graph? I was looking for Illinois, which isn’t there. Thanks!
What do you think about the conclusion here that we’re seeing a “…systemic effect where something about the pandemic made schools worse…”?
https://www.astralcodexten.com/p/what-happened-to-naep-scores
Have you considered expanding this analysis to the global level? I know standardized tests are different in different countries, but there is probably still something to be learned there.
It already exists. Check our PISA (and similar assessments):
https://en.m.wikipedia.org/wiki/Programme_for_International_Student_Assessment
Thank you for writing about this important topic and providing data. My question is what do we currently do now for children who are behind? My 4th grader is at least one year behind in math and struggles with reading comprehension. She is in intervention groups and has done private tutoring. All are helpful but nothing seems to be making up for the time lost. The school psychologist assures me my child is average and most kids in 4th are behind and need intervention. In my opinion, it seems as though these kids are being pushed through the system. What can we do in real time to help these kids who were affected? Thank you!
It seems some states are changing their cut scores for who is determined to be proficient to make their scores look better. If we continue to do these tests, the standards must remain the same year over year.
https://www.thefp.com/p/american-educators-lowering-cut-scores-declining-standards-reading-math?utm_campaign=posts-open-in-app&triedRedirect=true
In Seattle, where I am, many parents with means decamped to private school during the pandemic, partly because public schools stayed closed for so much longer. A lot of those families have stayed in the private school system. I imagine that less of this happened in Mississippi because there’s less wealth and fewer private school options. So could some of the persistent declines represent a sampling bias resulting from certain families with higher than average test scores leaving public schools?
Great point. Also a lot of kids in WA “disappeared” from the school systems, and are presumed to be unofficially homeschooling. The prevalence of those things could skew the numbers.
Thank you for writing about this topic! I am an educational researcher and I deeply appreciate the work the U.S. Dept of Education does to support students and their families. We very much need the data – and the research the Dept of Ed funds and disseminates – to figure out impactful, cost-effective ways to improve education. I really appreciate you highlighting this aspect of what the Dept of Ed does (and what it doesn’t do).